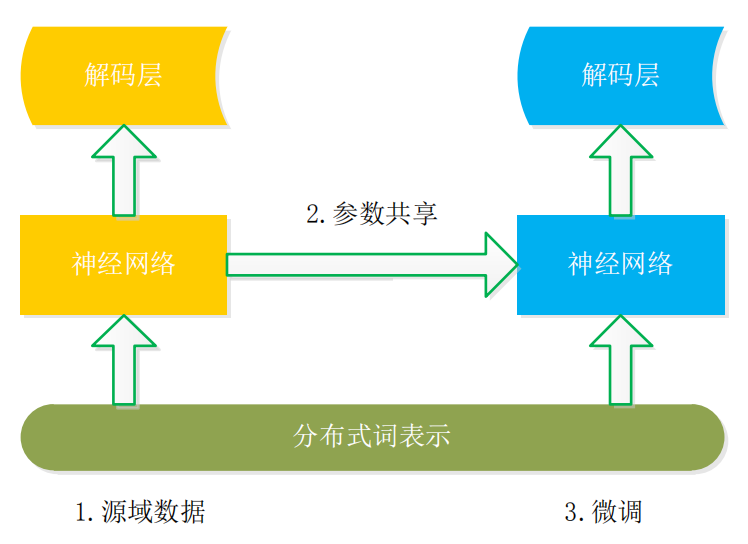
(2)共享参数。共享词嵌入侧重于词义的表示,而共享参数则侧重于模型参数的迁移。例如,Jason 等人从神经网络迁移机制以及迁移哪些层进行大量实验,实验结论显示浅层网络学习知识的通用特征,具有很好的泛化能力,当迁移到第 3 层时性能达到饱和,继续迁移会导致“负迁移”的产生。Giorgi 等人基 于 LSTM 进行网络权重的迁移,首先将源领域模型参数迁移至目标领域初始化,之后进行微调使适应任务需要。而 Yang 等人从跨领域、跨应用、跨语言迁移出发测试模型迁移的可行性, 在 一 些 benchmarks 上实现了 state-of-the-art。整体而言,在处理 NER 任务时良好的语义空间结合深度模型将起到不错的效果,在迁移过程中模型层次的选择和适应是难点。
基于特征变换的NER方法
在面向少量标注数据 NER 任务时,我们希望迁移领域知识以实现数据的共享和模型的共建,在上文中我们从模型迁移的角度出发,它们在解决领域相近的任务时表现良好,但当领域之间存在较大差异时,模型无法捕获丰富、复杂的跨域信息。因此,在跨领域任务中,一种新的思路是在特征变换上改进,从而解决领域数据适配性差的问题。基于特征变换的方法是通过特征互相转移或者将源域和目标域的数据特征映射到统一特征空间,来减少领域之间差异的学习过程,下面主要从特征选择和特征映射的角度进行探讨。
基于知识链接的 NER,即使用本体、知识库等结构化资源来启发式地标记数据,将数据的结构关系作为共享对象,从而帮助解决目标 NER 任务,其本质上是一种基于远程监督的学习方式,利用外部知识库和本体库来补充标注实体。例如 Lee 等人的框架(如图 6),在 Distant supervision 模块,将文本序列与 NE词典中的条目进行匹配,自动为带有 NE 类别的大量原始语料添加标签,然后利用 bagging和主动学习完善弱标签语料,从而实现语料的精炼。一般而言,利用知识库和本体库中的链接信息和词典能实现较大规模的信息抽取任务,这种方法有利于快速实现任务需求。
图6 知识链接与数据增强结合模型
(1)基于知识库。这种方式通常借用外部的知识库来处理 NER、关系抽取、属性抽取等任务,在现实世界中如 Dbpedia、YAGO、百度百科等知识库存在海量结构化信息,利用这些知识库的结构化信息框、日志信息可以抽取出海量知识。例如,Richman 等人利用维基百科知识设计了一种 NER 的系统,这种方法利用维基百科类别链接将短语与类别集相关联,然后确定短语的类型。类似地,Pan 等人利用一系列知识库挖掘方法为 200 多种语言开发了一种跨语言的名称标签和链接结构。在实践中,较为普遍的是联合抽取实体和实体关系。例如Ren 等的做法,该方法重点解决领域上下文
无关和远程监督中的噪声问题,其基本步骤为:
1、利用 POS 对文本语料进行切割以获得提及的实体;
2、生成实体关系对;
3、捕获实体与实体关系的浅层语法及语义特征;
4、训练模型并抽取正确的实体及关系。
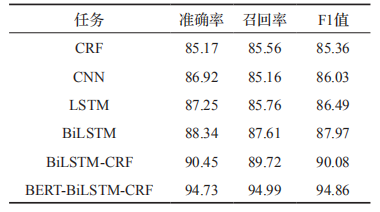
在 NYT 等语料上进行实验(如表 2),基于知识库的方法相较于基线方法有显著提高。
于图表示的句子模型中抽取特定的实体和实体关系实例。同样地,李贯峰等人首先从 Web网页提取知识构建农业领域本体,之后将本体解析的结果应用在 NER 任务中,使得 NER 的结果更为准确。这些方法利用本体中的语义结构和解析器完成实体的标准化,在面向少量标注的 NER 中也能发挥出重要作用。
四种方法比较
上述所介绍的 4 种面向少量标注的 NER 方法各有特点,本文从领域泛化能力、模型训练速度、对标注数据的需求和各方法的优缺点进行了细致地比较,整理分析的内容如表 3 所示。
本文深入探讨了NoSQL数据库的四大主要类型:键值对存储、文档存储、列式存储和图数据库。NoSQL(Not Only SQL)是指一系列非关系型数据库系统,它们不依赖于固定模式的数据存储方式,能够灵活处理大规模、高并发的数据需求。键值对存储适用于简单的数据结构;文档存储支持复杂的数据对象;列式存储优化了大数据量的读写性能;而图数据库则擅长处理复杂的关系网络。每种类型的NoSQL数据库都有其独特的优势和应用场景,本文将详细分析它们的特点及应用实例。 ...
[详细]





 。
。









 京公网安备 11010802041100号
京公网安备 11010802041100号